Дата: 17.04.2022 г.
Автор статьи: Илья Николаев — Эксперт по машинному обучению в Альтирикс Групп
Что такое машинное обучение
Машинное обучение обозначает множество математических, статистических, вычислительных методов для разработки алгоритмов. Данная область лежит на пересечении искусственного интеллекта, математики и программирования. Данные алгоритмы способны решить задачу не прямым способом, а на основе поиска закономерностей в разнообразных входных данных.
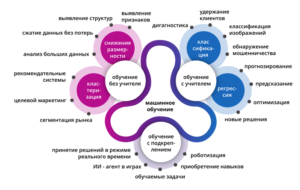
Можно выделить 3 основных типа машинного обучения:
1 тип — это обучение с учителем, которое предполагает полный набор размеченных данных для тренировки модели на всех этапах ее построения. Данные, подготовленные для анализа, изначально содержат правильный ответ, что и выступает в роли учителя. Поэтому цель алгоритма — выявление взаимосвязи и общих закономерностей. Результатом обучения такого алгоритма будет возможность сделать корректное предсказание.
2 тип — это обучение без учителя. В данном типе тоже есть некоторый набор данных, но в этом случае у нас уже нет никаких истинных ответов, алгоритм пытается самостоятельно найти корреляцию в данных, извлекая полезные признаки и анализируя их. На основе выявленных закономерностей алгоритм интерпретирует и систематизирует данные.
3 тип — это обучение с подкреплением. Данный тип основан на системе стимулов, т.е. вознаграждений и наказаний. Алгоритм пытается найти оптимальные действия, которые будет предпринимать, находясь в различных сценариях. Эти действия могут иметь как краткосрочные, так и долгосрочные последствия. От алгоритма требуется обнаружить эти связи.
Принципы и задачи машинного обучения
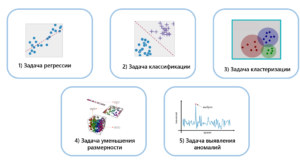
Задачи, которые способны решать данные алгоритмы, напрямую определяют выгоды для бизнеса. Можно выделить 5 основных задач, которые решают алгоритмы машинного обучения:
Задача регрессии — прогноз на основе выборки объектов с различными признаками. На выходе должно получиться какое-либо вещественное число. Предположим, мы предсказываем стоимость квартиры по прошествии некоторого промежутка времени.
Задача классификации. В данном случае мы получаем категориальный ответ на основе набора признаков, и в этом случае мы имеем конечное количество ответов. Например, в формате «да/нет». Например, «Есть на изображении человеческое лицо?» — «да или нет».
Задача кластеризации — распределение данных на группы. Например, разделение клиентов мобильного оператора по уровню платежеспособности.
Задача уменьшения размерности, т.е. в данном типе мы сводим большее число признаком к меньшему, либо для сжатия данных, либо для последующей визуализации.
Задача выявления аномалий. На первый взгляд, она очень похожа на задачу классификации, однако отличается тем, что аномалии — достаточно редкие явления и в обучающей выборке их может быть очень мало или они вообще могут отсутствовать. Поэтому классические методы, которые работают в классификации, здесь неприемлемы. На практике обычно такой задачей является выявление мошеннических действий с банковскими картами.
Первые две задачи относятся к типу обучения с учителем, т.к. у нас здесь есть истинные ответы, и данные изначально различаются. Задачи 3-5 относятся к типу обучения без учителя.
Тенденции развития машинного обучения
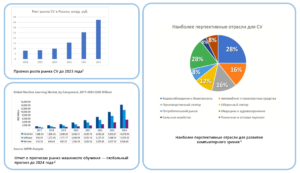
Машинное обучение сейчас активно развивается и в России, и за рубежом. На рисунке ниже представлена гистограмма отчета о прогнозах рынка машинного обучения до 2024 г. Здесь у нас представлены прогнозы и для услуг, и для программного обеспечения, и для аппаратного обеспечения. Если мы сравним рынок за прошедший 2021 г., который оценивался примерно в 10 млрд. долларов, то к 2024 г. он должен вырасти по прогнозу более чем в 3 раза.
Очень популярная область в машинном обучении — это Computer Vision (CV) или Компьютерное зрение. За прошедший 2021 г. рынок оценивался в чуть больше, чем 15 млрд. рублей, и к 2023 г. он должен вырасти более чем в 2 раза. Также здесь стоит отметить некоторые наиболее перспективные отрасли для CV. Самыми перспективными являются видеонаблюдение и безопасность, а также медицина и здравоохранение. Далее, данные алгоритмы также популярны в отраслях автомобилей и транспортных средств, в производственном секторе. Замыкают круг отрасли потребительского рынка, сельское хозяйство, розничная и оптовая торговля, оборонный сектор. Таким образом CV в данный момент применяется в достаточно многих областях.
Оптимизация работы с помощью ML
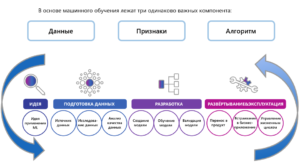
Каким же образом можно оптимизировать работу бизнеса с помощью алгоритмов машинного обучения? Во-первых, нужно отметить, что в основе машинного обучения лежат три одинаково важных компонента:
Данные, на которых модель обучается.
Признаки, на основе которых модель выявляет общие закономерности.
Cам алгоритм или модель.
Для того, чтобы оптимизировать работу бизнес-процесса, для начала необходимо определиться с идеей, т.е. найти процесс, который можно либо автоматизировать, либо ускорить, либо ввести дополнительную аналитику для оптимизации предприятия или для увеличения прибыли. После того, как мы определились с идеей, следующий этап — это подготовка данных. Нам необходимо найти источник данных (в большинстве случаев его либо нет, либо его сбор нужно подкорректировать). После того, как мы собрали некоторый набор данных/базу данных/датасет, идет анализ качества данных, т.е. «выбрасываются» данные, которые могут отрицательно, негативно повлиять на итоговое качество модели. Далее идет исследование данных на различные статистики, смотрится на корреляции данных, при необходимости исключаются некоторые признаки или формируются новые. Далее в некоторых случаях будет необходимо разметить датасет и далее датасет разбивается на обучающую и тестовую выборки. Собственно, обучающая выборка идет для тренировки модели, тестовая — для оценки качества работы алгоритма после его обучения.
Следующий этап, после того как мы собрали данные, — этап разработки. На данном этапе подбирается алгоритм, который наиболее подходящим образом решает поставленную задачу, подбираются гиперпараметры, функции, на которых будет оптимизироваться алгоритм, и метрики качества, на которых мы будем оценивать, насколько хорошо алгоритм справляется со своей работой после обучения. Далее идет обучение модели и тестирование на заранее подготовленном тестовом множестве. Данный этап разработки может занимать несколько итераций, и по итогу мы получаем модель, которая удовлетворительно справляется по нашей выбранной метрике качества с поставленной задачей.
Последним этапом является развертывание и эксплуатация. Идет перенос продукта и встраивание его в бизнес-приложение. Модель дополнительно тестируется уже на реальных данных, и, в случае необходимости, дополнительно дообучается. Если все работает корректно, следующим шагом идет управление жизненным циклом и поддержка модели.
Приведу несколько примеров использования машинного обучения в различных сферах, а именно:
В автоматизации производства можно использовать для обнаружения аномалий на предприятиях, для контроля качества продукции, для контроля безопасности персонала.
В розничной торговле можно использовать для прогноза продаж на ближайшее будущее, для управления запасами.
В маркетинге и продажах — для прогноза оттока клиентов, аналитики по отзывам клиентов.
В медицине — для выставления предварительных диагнозов как по табличным данным, так и по медицинским снимкам.
В безопасности — это фильтрация спама или обнаружение мошенничества.
Практические примеры использования ML
Обнаружение промышленных дефектов
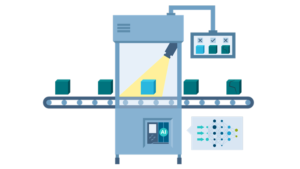
Первый практический пример применения машинного обучения — это обнаружение промышленных дефектов. Производственные процессы создают достаточно большой объем продукции с минимальным промежутком по времени (миллисекунды и секунды). Возникает необходимость выявлять дефекты в режиме реального времени с высокой точностью, тем самым оптимизировав производство. Алгоритмы компьютерного зрения позволяют выполнить заявленные требования. На рисунке ниже представлена принципиальная схема такой системы.
Общий принцип работы системы следующий: видеопотоки с камер поступают на целевые устройства (микрокомпьютеры или на сервер), на которых происходит анализ изображения с помощью алгоритмов машинного обучения. В результате определяется наличие, тип дефекта, ограничивающие рамки и маска изображения. На основе входных данных модели можно выдавать предупреждения операторам конвейера или вызывать другие системы оповещения. Входные и выходные данные прогнозирования могут быть захвачены и синхронизированы с сервером для дальнейшего анализа. Состояние и производительность моделей и периферийных устройств, анализ полученных данных можно дополнительно отслеживать на сервере.
План внедрения системы следующий:
На первом этапе происходит установка и подбор подходящего периферийного оборудования, датчиков и камер. Камеры могут варьироваться по углу обзора и разрешению в зависимости от поставленной задачи. На производственной линии для захвата изображения продукта устанавливаются подключаемые к локальной сети камеры с низким уровнем задержки и хорошим постоянным освещением.
На втором этапе происходит сбор данных для обучения модели, т.е. идет захват снимков продукции на конвейерной ленте с помощью камер. Собранный датасет должен содержать примеры как дефектных, так и исправных продуктов.
На третьем этапе идет разметка датасета. Дефектные изображения подвергаются дополнительной аугментации, чтобы уменьшить дисбаланс классов. Все полученные изображения аннотируются с помощью инструментов маркировки изображений, чтобы включать метаданные, такие как классы дефектов, ограничивающие рамки и, в случае необходимости, маски сегментации.
На четвертом этапе происходит обучение модели. Запускается рабочий процесс построения модели, включающий последовательность шагов, состоящих из предобработки данных, обучения модели и постобработки.
На пятом этапе происходит тестирование модели. Модель тестируется на заранее подготовленном тестовом датасете, либо на самом производстве. В случае необходимости, модель дополнительно дообучается.
На шестом этапе происходит постобработка и внедрение, которые включают в себя компиляцию модели, оптимизацию и установку для развертывания в целевой пограничной среде выполнения.
К результатам введения системы на производстве можно отнести:
значительное уменьшение количества бракованной продукции;
снижение эксплуатационных расходов;
сохранение времени выхода продукции на рынок;
повышение производительности, качества и безопасности всего предприятия.
Следующий кейс — это контроль наличия товаров на полке, достаточно актуальная проблема в данный момент. Исследование в области товаров ежедневного спроса показало, что если потребитель не может найти необходимый товар, то 45% из них выберут другой, аналогичный товар, 40% уйдут без товара, 15% уйдут к конкуренту и приобретут необходимый товар там. Т.е. в больше чем половине случаев мы можем потенциально потерять клиентов. Здесь необходимо ввести такие понятия, как OSA (On Shelf Availability) — это оценка наличия товаров на полке, показатель которого измеряется в процентах. И обратный к нему OOS (Out of Shelf) — это показатель упущенных продаж.
Согласно статистике от Международной Некоммерческой Организации ECR (Efficient Consumer Response), характеризующей важность введенных ранее показателей для поставщиков и ритейлеров, в среднем всего 20% позиций в статусе упущенных продаж (OOS) пополняется в течение 8 часов. 8,3% — это средний показатель упущенных продаж по индустрии в мире, который не изменяется последние 8 лет. Повышение процента заполненности полок на 3% принесет постепенный рост в 1% объема поставок для поставщика, а 2% принесет 1% постепенного роста объема продаж для розницы.
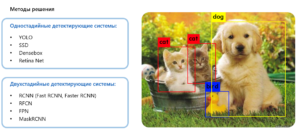
Данную задачу можно, как и первый кейс, решать с помощью алгоритмов компьютерного зрения. Как и в первом кейсе, можно использовать глубокие сверхточные нейронные сети. Ниже представлено несколько популярных решений детектирующей системы:
Одностадийные детектирующие системы:
YOLO
SSD
Densebox
Retina Net
Двухстадийные детектирующие системы:
RCNN (Fast RCNN, Faster RCNN)
RFCN
FPN
MaskRCNN
Результатом работы большинства из этих алгоритмов будет ограничивающая рамка, внутри которой находится детектируемый объект — класс, к которому относится данный объект и вероятность отнесения данного объекта к этому классу.
Здесь возникают некоторые проблемы со сбором датасета. Для того, чтобы модель получилась стабильной и с высокой точностью работы, необходимо собрать разнообразный и размеченный датасет, на что уйдет достаточно много времени, и все равно в итоге мы получим не совсем то, что хотим. В этом случае приходит на помощь создание 3D-сцен с 3D-моделями товаров, т.е. на основе снимков можно создать 3D-модель товара, а далее сделать 3D-сцену полок с данным товаром. Здесь мы решаем несколько проблем: во-первых, у нас будет очень разнообразный датасет для обучения модели, а во-вторых, заранее будем знать, какой товар куда поместили, и не нужно будет его дополнительно размещать. Результатом работы такого алгоритма будет выявление процента заполненности полок, и в случае, если данный процент падает ниже какого-либо порога, то идет сообщение либо менеджеру магазина, либо поставщику для пополнения.
Результаты:
Технологии компьютерного зрения можно установить на складах для мониторинга уровня запасов, а мониторинг в магазине может предупреждать предприятия о необходимости дополнительных продуктов.
Автоматизируя процесс управления запасами, розничные предприятия могут ожидать улучшения результатов от своих цепочек поставок и, в конечном итоге, большей прибыли.
Потенциальные выгоды от внедрения автоматизированного контроля за наличием товаров на полке могут составить до 5% в товарообороте.
Автоматизированный мониторинг соблюдения требований промышленной безопасности
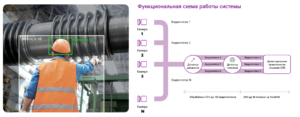
Следующий пример — это автоматизированный мониторинг безопасности и соблюдения нормативных требований для сведения к минимуму несчастных случаев и повышения эффективности работы предприятия. Ниже представлена функциональная схема работы такой системы.
У нас есть некоторое количество камер, которые полностью захватывают всю область видимости предприятия. Видеопотоки с данных камер поступают на целевые устройства (либо на локальные машины, микрокомпьютеры, либо на сервер), где происходит анализ изображений. В результате чего происходит обнаружение человека и, к примеру, наличие строительной каски на нем. Предпосылки к внедрения такой системы будут следующие:
штрафы надзорных органов;
несчастные случаи, которые зачастую обходятся работодателю примерно в 200 тыс. руб.;
компенсационные выплаты;
имиджевые потери;
остановка работ;
бракованная продукция;
неоптимальная численность персонала при несчастном случае.
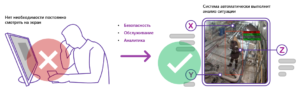
Автоматизированный мониторинг безопасности позволяет не смотреть постоянно на экран и не выделять на эту работу отдельного человека, который будет наблюдать за соблюдением техники безопасности на производстве. Система автоматически выполняет анализ ситуации, детектирует нарушения, и, в случае возникновения оного, производится быстрый визуальный контроль по цветовой индикации пиктограмм. Соответственно, идет, например, освещение и раскрытие изображения на весь экран. Также система предоставляет мгновенный доступ к изображению и архиву любой из камер, событиям о нарушениях в строке события с указанием даты и времени. Таким образом в случае совершения нарушения, система автоматически формирует отчет о нарушениях регламентов и техники безопасности.
C помощью данных систем можно фиксировать следующее:
ношение каски, подборочного ремня;
ношение защитного щитка (можно разбить на классы: опущен, поднят, частично поднят);
контроль того, что одежда полностью или частично застегнута, различие типов спец. одежды;
трекинг персонала.
К результатам внедрения системы можно отнести:
снижение травматизма персонала при производстве работ;
повышение трудовой дисциплины в части правильности применения средств индивидуальной защиты (СИЗ) за счет обеспечения обнаружения до 100% случаев нарушений техники безопасности;
подержание имиджа компании в глазах персонала как современной инновационной компании в эпоху цифровой трансформации;
выполнение требований Указа Президента РФ от 06.05.2018 г № 198 «Об основах государственной политики Российской Федерации в области промышленной безопасности на период до 2025 года и дальнейшую перспективу» и других нормативных актов.
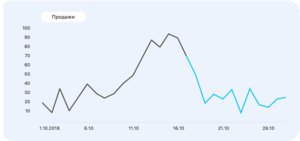
Следующий кейс — это прогнозирование продаж в кафе. Предположим, у нас есть хлебобулочное кафе с продажей хлебобулочных изделий, которые являются скоропортящимися. Здесь возникает несколько проблем: во-первых, конечный покупатель не может найти конкретный товар, который бы хотел приобрести к определенному часу; во-вторых, это наличие пищевых отходов к концу рабочего дня. Решением данных проблем будет ежедневное прогнозирование продаж для каждого продукта, т.е. для каждой позиции на последующие семь дней алгоритм предсказывает, сколько будет продано товаров в данный день. Таким образом с помощью данного алгоритма можно добиться следующих целей — уменьшение оценки товаров, сокращение количества пустых полок и возможность предпринимателя расширять и делать богатый ассортимент товаров, не боясь понести какие-либо крупные финансовые потери.
Данные, которые используются для обучения таких моделей: временные ряды, т.е. данные по прошлым продажам, прошлые акции, скидки и цены. Также алгоритмы машинного обучения позволяют использовать и другие признаки, а именно характеристику товаров, данные об отходах, информацию о кафе (расположение и размер), внешние данные (даты праздников, погода, ближайшие конкуренты). На основе вышеуказанных характеристик можно формировать производные показатели. Наиболее популярными методами решения проблемы являются Arima/Sarima – это алгоритмы, которые применяются в экономике. Далее идут алгоритмы, которые относятся к машинному обучению — это градиентный бустинг решающих деревьев, рекуррентные нейронные сети и ансамблирование нескольких подходов. Результатом работы алгоритмов будет график: черная кривая – результаты прошлых продаж, голубая кривая – результат работы алгоритма, т.е. его предсказание.
К результатам введения такой системы можно отнести:
уменьшение количества уцененного товара;
сокращение количества пустых полок;
повышение уровня удовлетворенности посетителя кафе;
возможность расширения ассортимента, не боясь понести какие-либо крупные финансовые потери.
Следующий пример – это системы пополнения складов darkstore. Она основана на предыдущих кейсах, о которых я рассказал, по прогнозированию спроса и контролю наличия товара на полке, которые позволят создать улучшенную систему выполнения запасов.
Преимущества следующие: во-первых, это эффективное использование доступного складского пространства, т.е. если мы будем в режиме реального времени знать процент заполненности полок, а также на ближайшие дни знать, сколько товара будет продано, то мы можем сделать алгоритм, который будет эффективно распределять товар на полках на складе или darkstore. Также к преимуществам можно отнести максимальную эффективность цепочки поставок, баланс риска, отсутствие запасов с риском потерь для каждого заказа на основе уровня запасов и спроса, высокий показатель доступности товара для конечного покупателя, оптимизация подбора товаров и снижение затрат на складирование.
Ниже представлю несколько кейсов применения машинного обучения в электроэнергетике.
Обнаружение аномалий в электропотреблении для обеспечения бесперебойной работы и предотвращения непредвиденных событий. Алгоритм машинного обучения может автоматически определять, например, тип объекта (супермаркет, средняя школа), а затем, исходя из электропотребления, обнаруживать и классифицировать аномалии в режиме реального времени.
Прогнозирование спроса на электроэнергию. Почасовое прогнозирование спроса в конкретный день с помощью алгоритмов машинного обучения позволит правильно распределять мощности производства и избегать финансовых убытков.
Формирование оптимальной цены электроэнергии. Модель оптимизации цен использует возможности машинного обучения для прогнозирования спроса на потребление энергии и выдачи оптимальных рекомендаций по ценообразованию.
Прогнозирование затрат и сбоев, вызванных простоем строительного и электрооборудования. Обнаружение аномалий и оповещение в режиме реального времени позволяют отслеживать состояние оборудования и максимизировать время безотказной работы.
Обнаружение кражи электроэнергии. На основе анализа временных рядов, исторических данных о клиентах с помощью алгоритмов машинного обучения можно обнаружить нарушения, указывающие на кражу или мошенничество. Это могут быть необычные всплески использования, различия между зарегистрированным и фактическим использованием или даже доказательства подделки оборудования.
Компьютерное зрение можно использовать для считывания показаний аналоговых датчиков на электроподстанциях и другом оборудовании, которое может находиться в труднодоступных местах. Камеры с компьютерным зрением используются для автоматического считывания показаний, например указателей уровня масла, температуры обмотки и указателей плотности газа.
Обнаружение коррозий
Коррозия является основным дефектом структурных систем, оказывает значительное экономическое воздействие и может представлять угрозу безопасности, если оставлять дефекты без присмотра. Задачи проверки, которые должны выполняться периодически, часто выполняются вручную и опять же в достаточно опасных условиях. Ручной процесс интерпретации обычно очень дорог, требует много времени и субъективен, поэтому методы глубокого обучения анализируют видеоизображение с камер для автоматизации задачи проверки, где ключевым показателем при осмотрах является наличие коррозии. Компьютерное зрение успешно применяется в случаях автоматического обнаружения ржавчины, что приводит к экономии средств и более быстрому принятию решений о профилактических и корректирующих мерах на основе количественных данных в масштабе.
Автоматическое наматывание тросов
В нефтяной и газовой промышленности тросы используются для внутрискважинных работ и оценки пласта. В то время, как комплект инструментов извлекается из скважины, трос, обычно натянутый, наматывается на барабан. Неправильная намотка может привести к серьезному повреждению кабеля. Алгоритмы компьютерного зрения дают возможность для обнаружения аномалий наматывания и прогнозирования положения кабеля в режиме реального времени.
Система обнаружения вторжений (информационная безопасность)
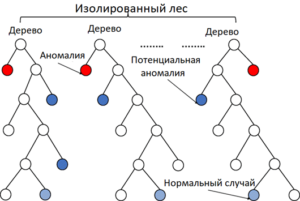
Система обнаружения вторжений — это кейс, который выполнен нашей компанией с использованием алгоритмов машинного обучения. Система обнаружения вторжений — это программное и аппаратное средство, предназначенное для выявления фактов неавторизованного доступа в компьютерную систему или сеть, либо несанкционированного управления ими, в основном через интернет. Как правило, в результате таргетированной атаки злоумышленники закрепляются в инфраструктуре сети, подстраиваются под сетевой трафик и остаются незамеченными долгий промежуток времени. Здесь важно отметить, что стандартные методы обнаружения вторжений слишком статичны и не всегда способны обнаружить целевую атаку, поэтому алгоритм машинного обучения позволяет выявлять такие таргетированные атаки за счет своей адаптивности и обобщающей способности.
В компании использовался алгоритм Isolation Forest (изолированный лес), в основе которого лежит более простой алгоритм, а именно деревья решений. Модель на вход получает логи событий, которые заранее сгруппированы по отправителю и получателю. На выходе алгоритм выдает аномальные случаи (выбросы появляются ближе к корню дерева решений). В случае если количество аномалий превышает определенный порог (тогда в логах событий могут быть потенциальные вторжения) и система генерирует сигнал тревоги, который продается в стек ELK (Elasticsearch, Logstash и Kibana).
Были проведены пентесты, которые показали, что данный алгоритм более эффективно детектирует вторжения, чем стандартные статичные методы.
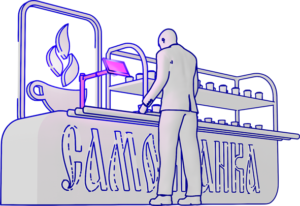
Устройство автономной торговли и маркетинга (УАТМ) «Самобранка»
Это разрабатываемый проект по продаже продукции в точке продаж без участия персонала. Проект разрабатывается нашей компанией. Здесь важно отметить несколько моментов: продажа продукции осуществляется без участия персонала, система позволяет контролировать и прогнозировать уровень продаж по продуктовым группам и календарю, прогнозировать пополнение запасов продукции. Данную систему можно применять в кафе бизнес-центров, в столовых в образовательных учреждениях, в ведомственных и корпоративных столовых и в предприятиях общепита.
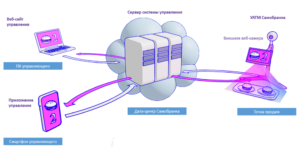
Основу системы составляет УАТМ Самобранка или устройство автономной торговли и маркетинга, включающее в себя микрокомпьютер, сенсорный экран, две камеры (одна направлена на корзину или поднос, вторая направлена непосредственно на покупателя), и терминал оплаты. С помощью компьютерного зрения за доли секунды система распознает товар на подносе или корзине и позволяет уменьшить вероятность возникновения очередей и значительно увеличить пропускную способность магазина либо кафе. Также с помощью средств компьютерного зрения УАТМ Самобранка позволяет определять полный возраст покупателя (с помощью второй камеры) и на экран выводится таргетированная реклама.
В системе также присутствует сервер управления, который собирает данные по сделанным покупкам с УАТМ и анализирует их с использованием алгоритмов машинного обучения. Данная аналитика позволяет оптимизировать процесс закупок и увеличить товарооборот, а, соответственно, и прибыль в кафе или магазине. Для предпринимателя данные по покупкам, а также анализ с помощью алгоритмов машинного обучения будет доступен через веб-сайт управления либо через мобильное приложение.
Я отмечу, что машинное обучение быстро становится основой технологий, которые органично внедряются во всех секторах бизнеса для решения сложных бизнес-задач, одновременно повышая эффективность и масштабируемость организации. И даже при всех сложностях, связанных с правильным внедрением машинного обучения, предприятия готовы взять на себя этот трудоемкий и относительно дорогой процесс, поскольку он дает ощутимые и существенные преимущества по сравнению с любым традиционным аналитическим методом. Хочется выделить преимущества и недостатки внедрения машинного обучения в бизнес-процесс.
К преимуществу можно отнести:
автоматизацию рутинных задач;
обработку больших объемов неструктурированных данных;
сокращение рабочего персонала (также и недостаток);
оптимизацию производства;
улучшение персонализации и эффективности маркетинга;
выявление трендов;
ускорение исследовательских циклов;
меньший процент ошибок и отсутствие человеческого фактора;
увеличение прибыли.
К недостаткам можно отнести следующее:
Зависимость модели машинного обучения от исходных данных — все модели обучаются на данных и итоговое качество работы модели напрямую зависит от того, на каких данных она обучалась, насколько они были качественные. Соответственно если датасет был собран не качественно, ожидать высокую точность работы алгоритма не следует.
Выявление ложных корреляций. Методы машинного обучения — это достаточно сложные математические модели. Бывает такое, что из данных они могут извлекать такие закономерности, которых в реальной жизни нет, что тоже может быть проблемой.
Отладка сбора данных. В случае, если источника данных нет, его необходимо формировать, а в большинстве случаев, когда он есть, его нужно донастраивать.
Поддержка моделей. Особенно касается тех, которые дообучаются в продакшене, т.е. необходимо дополнительно следить за работой модели.
Взлом модели. Например, в описании нейронной сети в байтовом виде могут встраиваться различные вирусы, которые предоставляют доступ к локальной машине или сети, и не сильно влияют на качество модели, а, соответственно, обнаружение таких вторжение достаточно затруднительно.
Снижение количества рабочих мест. Это можно отнести как к положительным чертам, так отрицательным.
Сложность точной оценки эффективности модели обучения для бизнеса. Это означает, что в некоторых случаях достаточно сложно оценить, какую итоговую прибыль принесло внедрение того, или иного решения (достаточно сложно оценить в конкретных цифрах).
Часто задаваемые вопросы (FAQ)
На каких машинах/устройствах обучается модель?
Обучение моделей происходит в облачном сервисе Yandex Cloud Datasphere, который предоставляет кластеры из центральных и графических процессоров (видеокарты типа Nvidia Tesla K100), что позволяет обрабатывать большие объемы данных и быстро обучать сложные модели с большим количеством параметров. Сервер можно арендовать, либо развернуть обработку на сервере компании, минимальные требования к характеристикам сервера зависит от сложности и количества параметров конечной модели машинного обучения.
Есть ли возможность локального использования машинного обучения?
Есть возможность запуска моделей машинного обучения на локальных машинах или микрокомпьютерах (например, Nvidia Jetson) без доступа к сети Интернет. Минимальные требования к характеристикам зависит от сложности и количества параметров конечной модели машинного обучения.
Какой процент ошибок в таких алгоритмах?
Нужно понимать, что алгоритмы машинного обучения — это сложные математические модели, качество работы таких моделей напрямую зависит от многих факторов:
Качества и разнообразности данных и разметки данных для обучения модели
Алгоритма и архитектуры модели
Оптимального подбора гиперпараметров модели
Оптимального подбора целевой функции и конечной метрики качества для оценки модели
Правильно сформированного тестового множества
При учёте данных факторов можно получить стабильную модель машинного обучения, которая быстро и правильно решает поставленную задачу. Качество работы алгоритма оценивается на заранее подготовленном тестовом датасете (данные, которые алгоритм ещё не видел) с помощью метрики качества. Когда алгоритм по метрике качества показывает приемлемые для решения текущей задачи результаты, алгоритм внедряется в производство и дополнительно тестируется в реальной условиях, в случае необходимости происходит дообучение алгоритма. Ошибки алгоритма не исключены даже после внедрения и тестирования, однако их количество будет сведено к минимуму и существенно меньше, чем у человека, решающего аналогичную задачу. В среднем ошибки можно свести к единицам процентов или даже к десятым долям процента.
Сроки введения в эксплуатацию?
Сроки введения в эксплуатацию зависят от размеров производства, количества рабочего персонала, изначальной оснащенности предприятия необходимым для мониторинга оборудованием и т.д. В среднем, уже через 6 месяцев разработки, можно получить тестовую модель.
Какие технологии используются в машинном обучении?
В продукте Альтирикс Групп УАТМ «Cамобранка» используются следующие языки программирования: Python3, C++, JavaScript; библиотеки и фреймворки: pythorch, sklearn, XGBoost, opencv, pandas, numpy, threading, multiprocessing, django, rest-api, plotly, tensor-rt, QT, tkinter.
Федеральным законом от 14.07.2022 № 266-ФЗ «О внесении изменений в Федеральный закон «О персональных данных», отдельные законодательные акты Российской Федерации и признании утратившей силу части четырнадцатой статьи 30 Федерального закона «О банках и банковской деятельности» вносится ряд изменений в Федеральный закон от 27.07.2006 № 152-ФЗ «О персональных данных»…
Обзор требований по импортозамещению, в том числе Указа Президента Российской Федерации от 30.03.2022 № 166 «О мерах по обеспечению технологической независимости и безопасности критической информационной инфраструктуры Российской Федерации» и Указа Президента Российской Федерации от 01.05.2022 № 250 «О дополнительных мерах по обеспечению информационной безопасности Российской Федерации»
Смотреть видео
511
Политика конфиденциальности
Политика конфиденциальности Альтирикс Групп (Редакция от 13.05.2020)
1. Общие положения
1.1. Настоящая Политика конфиденциальности (далее – Политика) Альтирикс Групп (далее – Компания) действует в отношении процессов сбора и обработки данных посетителей сайта altirixgroup.com (далее – Сайт).
1.2. Основные типы данных посетителей Сайта (далее – Пользователь):
Персональные данные (далее – ПДн) в составе электронных форм обратной связи, заполняемых Пользователем при использовании сервисов Сайта (формы обратной связи, кнопки «Связаться», «Заказать» и другие).
Техническая информация, включающая в себя сведения, автоматически получаемые сервером при доступе к Сайту (ip-адрес, версия браузера, прочее) и файлы «cookie» (текстовые файлы или фрагменты, сохраняемые браузером Пользователя на компьютере, смартфоне или ином устройстве).
2. Персональные данные
2.1. Для использования сервисов Сайта Пользователем могут быть указаны следующие ПДн: ФИО, контактные данные (email, телефон), место работы.
2.2. ПДн обрабатываются Компанией в следующих целях:
взаимодействие с Пользователем для возможного сотрудничества и/или заключения договора;
формирование и предоставление ответа на полученное обращение или запрос Пользователя;
предоставление Пользователю сведений о потенциально интересных Пользователю услугах или предложениях Компании.
2.3. Компания не передает ПДн Пользователя третьим лицам.
2.4. Электронные формы обратной связи предусматривают дополнительные поля для ввода произвольной информации на усмотрение Пользователя. Пользователю запрещается указывать в указанных полях ввода какие-либо ПДн.
2.5. После заполнения полей ввода, предусмотренных электронной формой обратной связи, Пользователь может нажать кнопку для отправки введенных сведений в адрес Компании. Этим действием Пользователь подтверждает свое согласие с обработкой своих ПДн в соответствии с условиями Политики.
3. Техническая информация
3.1. Техническая информация (в т.ч. файлы «cookie») используется для функционирования Сайта и повышения качества предоставляемых услуг. Информация в обобщенном виде (статистические данные) используется для оценки использование Сайта Пользователями.
3.2. Пользователь может самостоятельно посредством настройки браузера ограничить или исключить использование файлов «cookie» на Сайте. Такое ограничение может привести к некорректной или неполной работе Сайта.
3.3. При посещении Сайта Пользователю отображается уведомление о необходимости ознакомиться с Политикой и принять ее условия. В случае, когда Пользователь продолжает использовать Сайт, Компания считает, что Пользователь принял условия Политики.
3.4. На сайте используется сторонний сервис «Яндекс.Метрика» (ООО «ЯНДЕКС»), в связи с этим техническая информация может быть передана в указанную компанию для формирования аналитической информации об использовании Сайта.
4. Политика защиты
4.1. Все обрабатываемые данные Пользователей относятся к конфиденциальной информации. Компания выполняет все установленные законодательством меры по защите таких данных.
4.2. Обработка ПДн, полученных через электронные формы обратной связи, ведется в соответствии с требованиями законодательства Российской Федерации о ПДн.
5. Ответственность сторон
5.1. Компания вправе в любое время в одностороннем порядке изменять, дополнять и иным образом корректировать условия Политики без уведомления Пользователя.
5.2. Внесенные изменения вступают в силу с даты размещения новой версии Политики на Сайте. Дата внесения изменений в Политику указывается непосредственно в новой версии Политики. Пользователь должен самостоятельно проверять наличие новой версии Политики.
5.3. Пользователь имеет право не соглашаться с условиями Политики, в таком случае он не может использовать Сайт и его сервисы.
5.4. Пользователь имеет все права, установленные законодательством Российской Федерации, в отношении получаемых Компанией данных (п.2.1). В случае необходимости связаться по вопросам, связанным с реализацией этих прав, можно воспользоваться любой из электронных форм обратной связи и/или связаться с Компанией по контактным данным, указанным на Сайте в разделе «Контакты».
5.5. На Сайте могут содержаться ссылки на другие сайты, страницы, каналы. Компания не несет ответственности за их содержание и политику безопасности.